
Desmistificando a programação em machine learning
Machine learning usa algoritmos para entender o modelo que dá origem a um conjunto de dados para conseguir prever ou classificar novos valores
Por: Marcos Tanaka
Dirigir, investir, detect ar fraudes, classificar doenças e criar medicamentos. Há pouco tempo essas atividades eram feitas somente por seres humanos. Hoje, com o desenvolvimento de técnicas de aprendizado de máquina (machine learning, na sigla em inglês), podemos ensinar sistemas a executá-las com precisão igual – ou superior – a nossa.
ar fraudes, classificar doenças e criar medicamentos. Há pouco tempo essas atividades eram feitas somente por seres humanos. Hoje, com o desenvolvimento de técnicas de aprendizado de máquina (machine learning, na sigla em inglês), podemos ensinar sistemas a executá-las com precisão igual – ou superior – a nossa.
Machine learning usa algoritmos para entender o modelo (a lógica, o padrão) que dá origem a um conjunto de dados para conseguir prever ou classificar novos valores.
A programação tradicional baseia-se em definir cada etapa que o programa deve executar para obter um resultado. Com machine learning, a ideia é fazer com que ele aprenda os passos necessários para isto.
A grande vantagem ocorre quando trabalhamos com problemas complexos, onde o algoritmo não é bem definido. Como identificar pessoas em uma foto. É muito difícil escrever um programa que faça isto bem feito, pois a variedade de cenários possíveis é muito grande. Existe uma infinidade de poses, locais, ângulos, iluminação e cores em uma foto. Preparar um algoritmo para trabalhar com todos estes cenários é muito trabalhoso. Com machine learning podemos ensinar o computador a fazer esta tarefa sem programar o passo-a-passo, apenas ensinando com base em exemplos.
Podemos separar os algoritmos de machine learning conforme seu tipo de aprendizagem, ou seja, a forma como aprendem.
Tipos de aprendizagem
Existem três principais categorias: aprendizagem supervisionada, não supervisionada e por reforço.
Aprendizagem Supervisionada
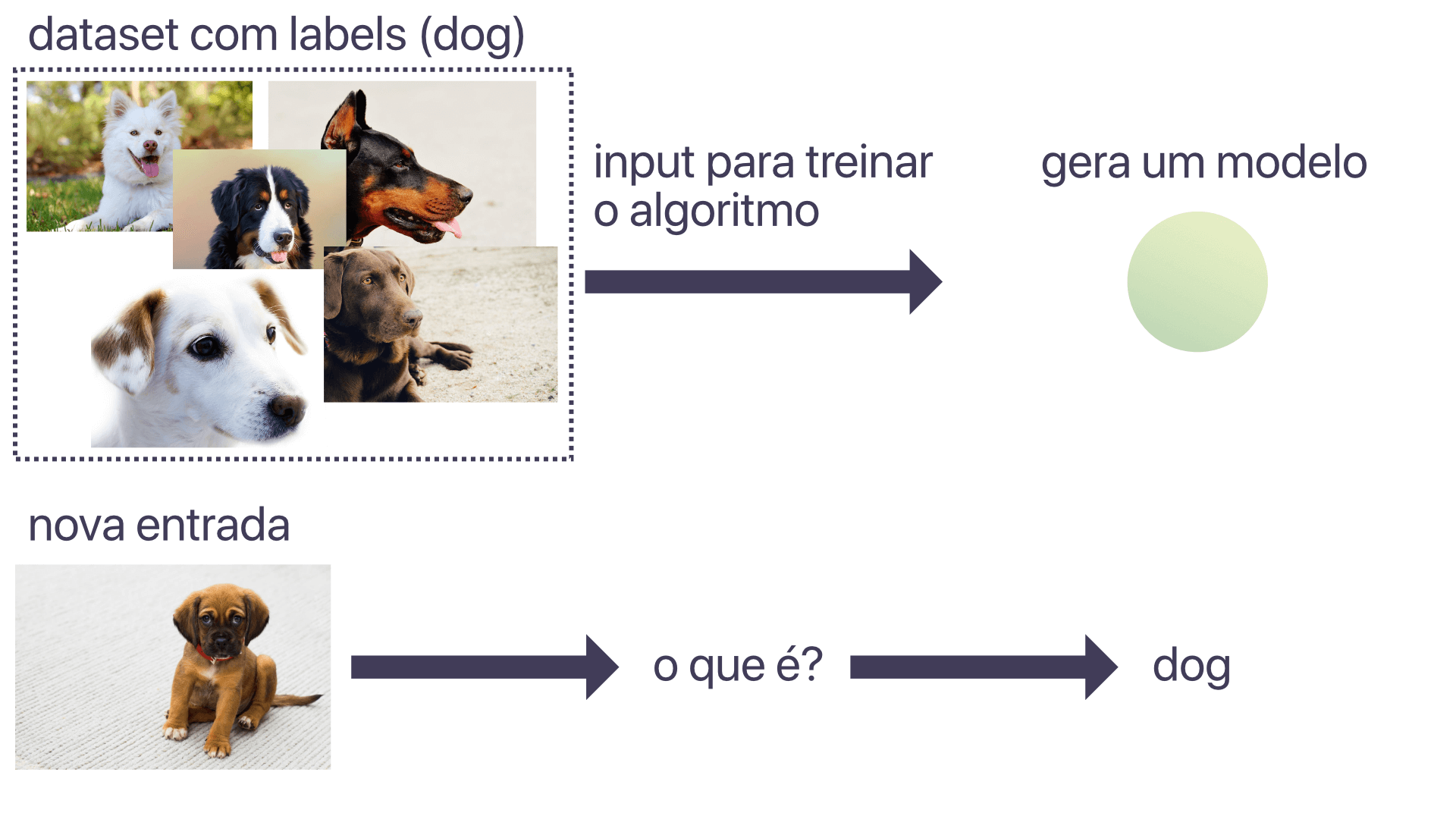
Imagine um programa que usa machine learning para identificar fotos de cachorros. Vou usar dois dados de entrada para treiná-lo:
Imagem: fotos variadas, algumas de cachorros, e outras não.
Boolean: um boolean que indica se a foto é ou não de um cachorro.
O treinamento ocorre quando o programa “vê” uma imagem junto com sua resposta, ou seja, esta imagem é de um cachorro? Imagine isto se repetindo para milhares de imagens diferentes. Chega um momento em que o programa identifica as características que fazem uma imagem ser a imagem de um cachorro.
Esta é a aprendizagem supervisionada: dizemos ao computador o que é cada entrada (qual o label) e ele aprende quais características daquelas entradas fazem elas serem o que são.
De acordo com o tipo de resultado do algoritmo, podemos classificá-lo entre algoritmo de classificação ou algoritmo de regressão.
O exemplo anterior é um exemplo de classificação. Estamos classificando uma entrada entre dois tipos possíveis: cachorro ou não-cachorro.
Já a regressão ocorre quando o resultado é numérico. Por exemplo, um programa que calcula o valor que uma casa deveria ter com base em características como número de quartos, localização e ano de construção. Com base em exemplos de casas similares, o computador aprende a precificar novas casas.
Aprendizagem Não Supervisionada

Nos três tipos de aprendizagem existe a semelhança do computador aprender a inferir algo com base em suas experiências passadas. A diferença da aprendizagem não supervisionada para a supervisionada é que aqui a aprendizagem ocorre com dados não rotulados, ou seja, não dizemos ao computador o que é aquela entrada.
Por exemplo, vamos imaginar uma distribuidora que quer classificar seus clientes em categorias. Ela cria um programa que usa aprendizagem não supervisionada para fazer isto. Ou seja, ela ensina a separar os dados em grupos semelhantes, sem dizer o que são estes grupos. Um possível resultado é um grupo de clientes que compram produtos frescos, e outro com clientes que compram produtos industrializados, por exemplo.
Da mesma forma com a classificação de imagens. Temos um modelo que aprendeu a classificar imagens entre dois grupos distintos. Ao receber uma nova imagem, com base em seus atributos, ele identifica a qual grupo ela pertence. Sem necessariamente saber o que é aquele grupo.
Aprendizagem Por Reforço

A terceira classificação é a aprendizagem por reforço. Imagine criar um programa responsável por dirigir um veículo autônomo. Ele deve aprender a dirigir pelas ruas e transportar seus passageiros. Existem diversas formas de otimizar esta tarefa. Por exemplo, chegar ao destino no menor tempo possível e não causar nenhum acidente. Queremos que ele saiba o que fazer conforme o que ocorre à sua volta, e preferimos que ele demore um pouco mais do que causar um acidente, por exemplo. A aprendizagem por reforço é uma forma de ensinar ao computador qual ação priorizar dada uma determinada situação.
É possível vincular recompensas e punições aos possíveis resultados e, ponderando-as da forma certa, ensinar o nível de prioridade de cada meta. Neste exemplo, posso atribuir uma punição muito maior em caso de um acidente em comparação a se atrasar poucos minutos. Desta forma se ensina quais ações o computador deve priorizar.
Existem muitos detalhes que não foram cobertos por este artigo, porque a ideia foi iniciar o assunto para que possamos entender um pouco do que é machine learning e como é implementar programas que utilizam este recurso.
Além de conhecer as técnicas para criar programas que usam machine learning, é preciso também prestar atenção aos dados que serão utilizados para treinar estes programas. Grande parte do sucesso de um modelo vem da qualidade desses dados. É possível tratá-los utilizando técnicas de Análise de Dados.
Fonte: Computer World
Texto original:
http://computerworld.com.br/desmistificando-programacao-em-machine-learning